There are over 600 million internet users in India, but only a fraction of this population is fluent in English. Most online services and much of the content on the web currently, however, are available exclusively in English.
This language barrier continues to contribute to a digital divide in the world’s second largest internet market that has limited hundreds of millions of users’ rendition of the world wide web to a select few websites and services.
So it comes as no surprise that American tech giants, which are counting on emerging markets such as India to continue their growth. are increasingly attempting to make the web and their services accessible to more people.
Case in point: A feature that Google provides to quickly translate the content of a web page from English to Indian languages has been used more than 17 billion times by users in India in the past year.
Google, which has so far led this effort, on Thursday unveiled some of its new efforts. The company — which counts India as its biggest market by users, and this year committed to invest more than $10 billion in the country over the coming years — said it plans to invest more in machine learning and AI efforts at Google’s research center in India and make its AI models accessible to everyone across the ecosystem. The company also plans to partner with local startups that are serving users in local languages, and “drastically” improve the experience of Google products and services for Indian language users.
On that last part, the company today announced a range of changes it is rolling out across some of its services to make them speak more local languages and unveiled a whole new approach it’s taking to translate languages.
Product changes
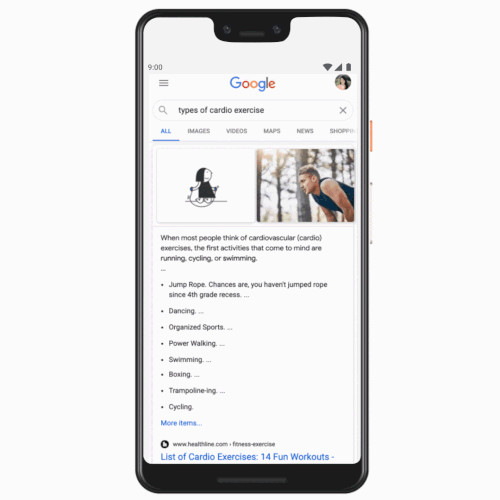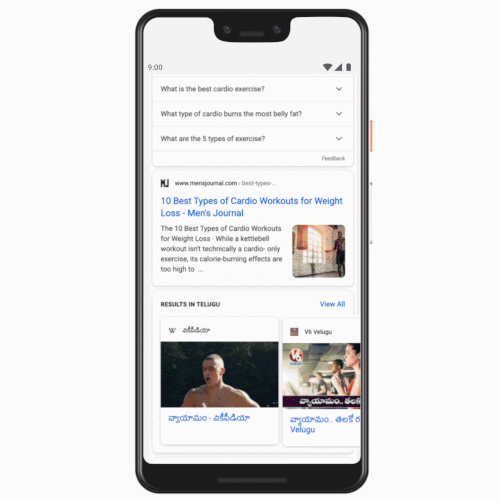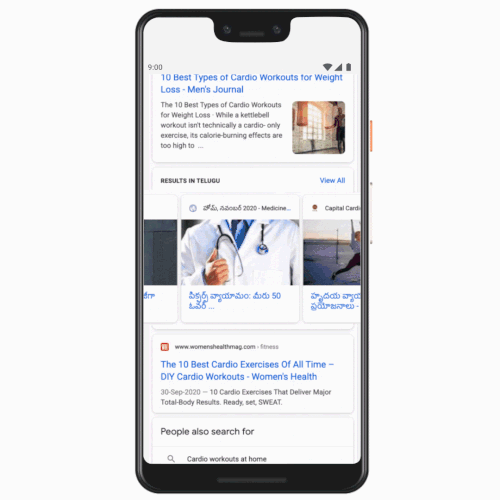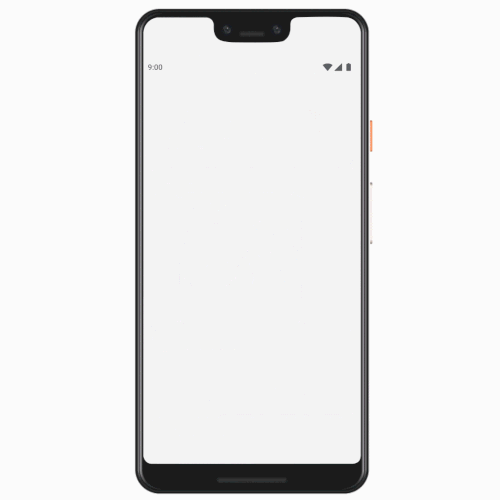
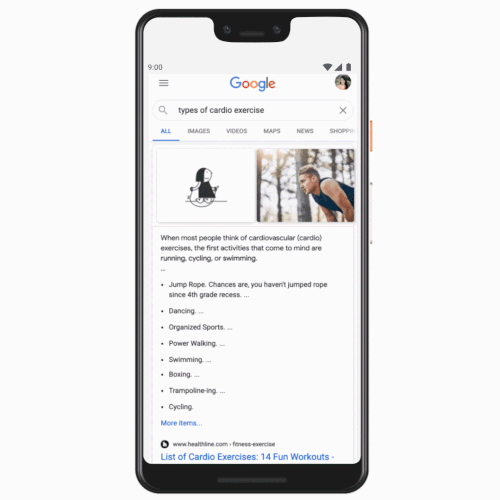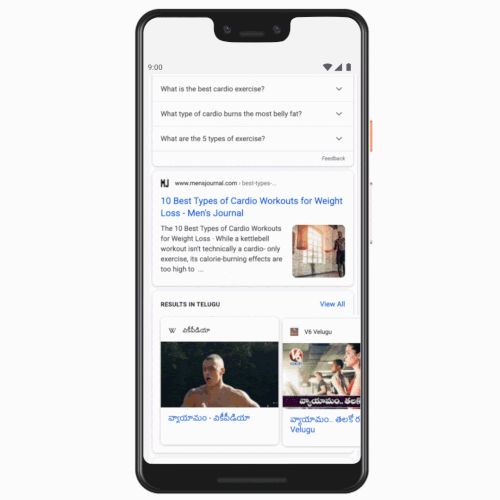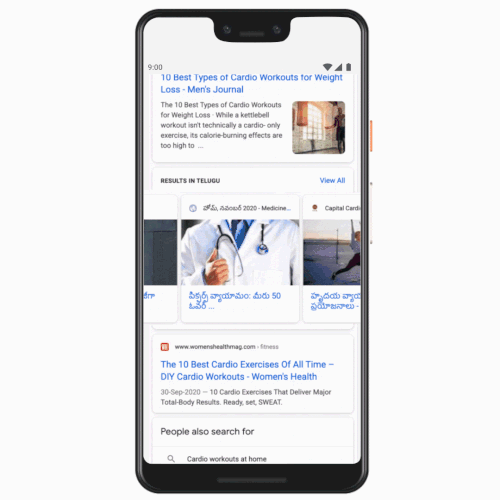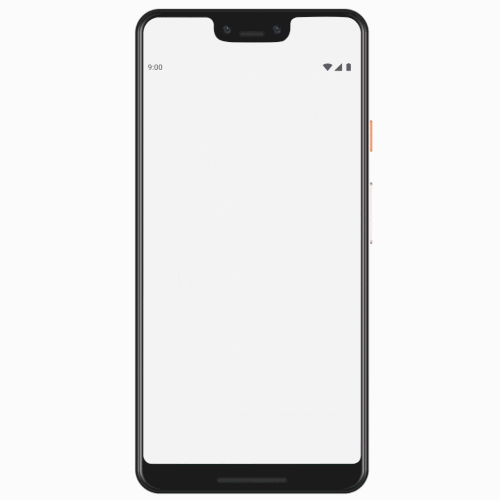
Users will now be able to see search results to their queries in Tamil, Telugu, Bangla, and Marathi, in addition to English and Hindi that are currently available. The addition comes four years after Google added the Hindi tab to the search page in India. The company said the volume of search queries in Hindi grew more than 10 times after the introduction of this tab. If someone prefers to see their query in Tamil, for instance, now they will be able to set Tamil tab next to English and quickly toggle between the two.
Getting search results in a local language is helpful, but often people want to make their queries in those languages as well. Google says it has found that typing in non-English language is another challenge users face today. “As a result, many users search in English even if they really would prefer to see results in a local language they understand,” the company said.
To address this challenge, Search will start to show relevant content in supported Indian languages where appropriate even if the local language query is typed in English. The feature, which the company plans to roll out over the next month, supports five Indian languages: Hindi, Bangla, Marathi, Tamil, and Telugu.

Google is also making it easier for users to quickly change the preferred language in which they see results in an app without altering the device’s language settings. The feature, which is currently available in Discover and Google Assistant, will now roll out in Maps. Maps supports 9 Indian languages.
Similarly, Google Lens’s Homework feature, which allows users to take a picture of a math or science problem and then delivers its answer and walks students through the steps on how to get there, now supports Hindi language. India is the biggest market for Google Lens, said Nidhi Gupta, Senior Product Manager at Google India, at the event.
Jayanth Kolla, chief analyst at consultancy firm Convergence Catalyst, said the new feature of Google Lens could pose a threat to some Indian startups such as Sequoia Capital-backed Doubtnut that operates in a similar space.
MuRIL
Google executives also detailed a new language AI model, which they are calling Multilingual Representations for Indian Languages (MuRIL), that delivers more efficiency and accuracy in handling transliteration, spelling variations and mixed languages and other nuances of languages. MuRIL provides support for transliterated text when writing Hindi using Roman script, which was something missing from previous models of its kind, said Partha Talukdar, Research Scientist at Google Research India, at a virtual event Thursday.
The company said it trained the new model with articles on Wikipedia and texts from a dataset called Common Crawl. It also trained it on transliterated text from, among other sources, Wikipedia (fed through Google’s existing neural machine translation models). The result is that MuRIL handles Indian languages better than previous, more general language models and can contend with letters and words that have been transliterated — that is, Google is using the closest corresponding letters of a different alphabet or script.
Talukdar noted that the previous model Google relied on proved unscalable as the company had to build model for each language separately. “Building such language specific modeling for each and every task is not resource efficient as we often don’t have training data for tasks like this,” he said. MuRIL significantly outperforms the earlier model — by 10% on native text and 27% on transliterated text. MuRIL, which was developed by Google executives in India and is being in use for about a year, is now open source.
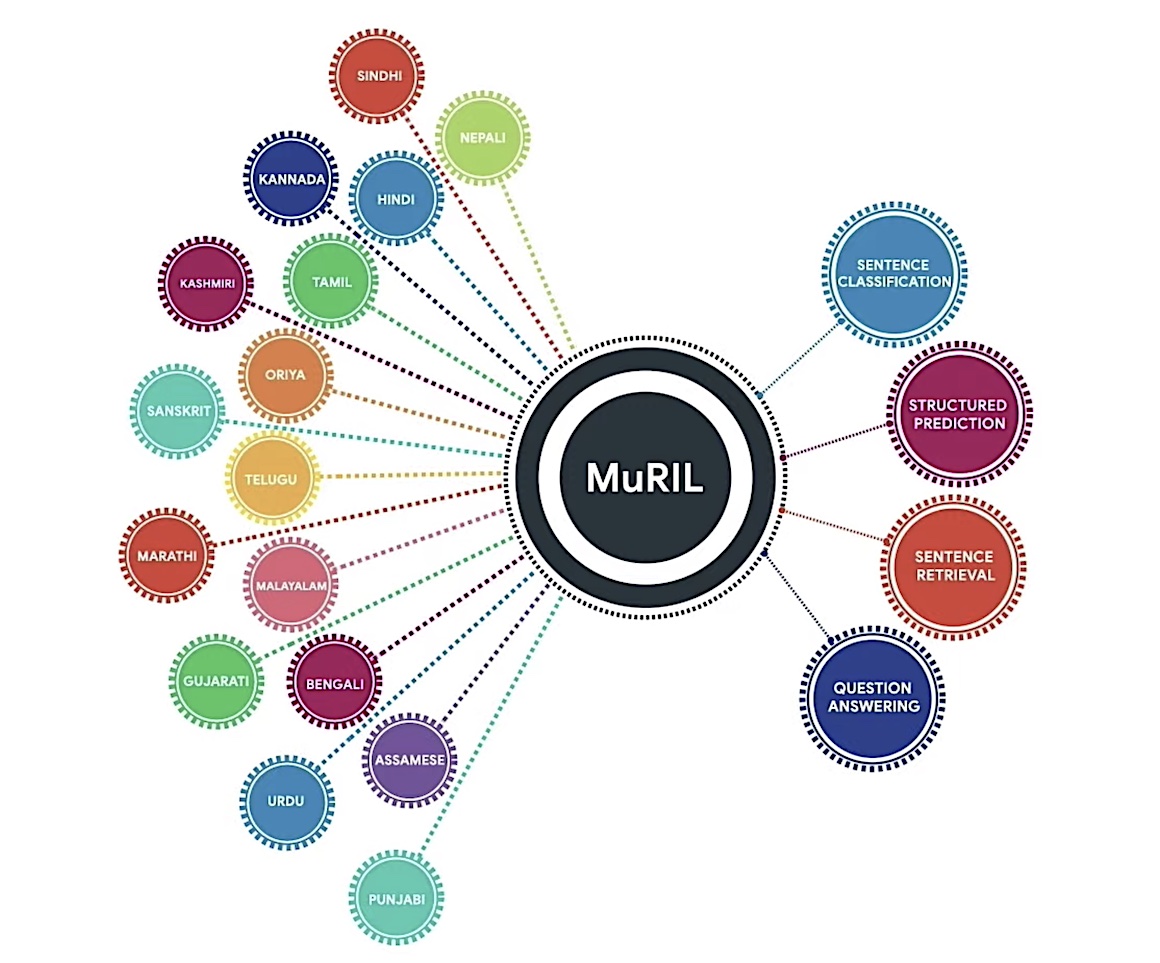
MuRIL supports 16 Indian languages and English.
One of the many tasks MuRIL is good at, is determining the sentiment of the sentence. For example, “Achha hua account bandh nahi hua” would previously be interpreted as having a negative meaning, but MuRIL correctly identifies this as a positive statement, said Talukdar. Or take the ability to classify a person versus a place: ‘Shirdi ke sai baba’ would previously be interpreted as a place, which is wrong, but MuRIL correctly interprets it as a person.











